

This post is about killing a database cluster. Please do not try this on a live environment, as you will wake up with a dead cluster. Recently while working on a client’s CRM project, we ran into some issues with MySQL GROUP_BY. Our queries in the application were throwing errors, and we needed to make some changes in the configuration of the Percona 5.7 database server’s parameters.
SET GLOBAL sql_mode=(SELECT REPLACE(@@sql_mode,’ONLY_FULL_GROUP_BY’,”));
We’re operating inside a SOC2 compliant environment, so we didn’t have direct root access to run this command. However, RackSpace provides an interface for this. For starters, racksspace support suggested that we use sql_mode = ” to test things out. The interface didn’t allow us to use this value, BUT it DID allow us to use a NULL value.
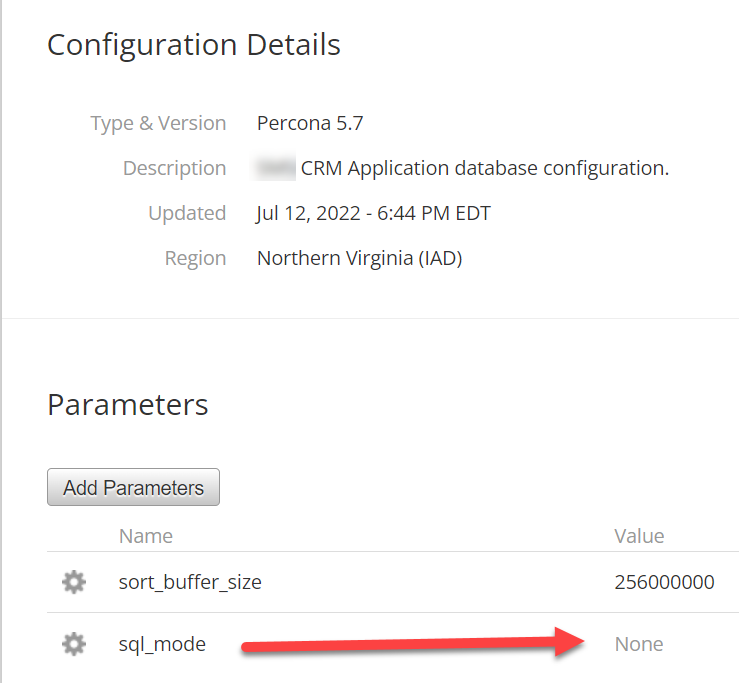
This is where things get interesting. The application stopped complaining and all was good, but noot for long! At midnight, during the replication process, one of the replicas went offline, and it was downhill from there.
Response from RackSpace
“The root cause was traced back to a bug that has been identified. Your custom configuration “SMS-CLUSTER-CONFIG” had a variable set to an empty value,
===
sql_mode
===
This was causing the configuration file on the Cloud Database instance to be written out without a value,
===[mysqld]
…
sql_mode
…
===
The replica build was failing as MySQL itself was refusing to start due to the invalid configuration.
As a work around I have explicitly set the “sql_mode” to be ” on the backend so that the config file would get written out correctly. I have opened a bug report with our Cloud Database engineers to investigate and fix.”
“As we’ve manually updated the backend database to contain the correct value for sql_mode, I don’t see how this exact behavior could be repeated. Unfortunately the bug you uncovered was regarding the sql_mode option which prevented the mysql daemon from starting ( and logging anything ).”
So, almost 24 hours after the incident, the cluster was back online, but only with one replica. It took RackSpace about 36 hours to get the cluster fully operational again. This goes to show that not even the most hardened systems are immune to complete failure. So how do you avoid this, and make your queries work perfectly? Use the below in the sql_mode paramter on the RackSpace Percona HA Cluster Configuration.
(allow_invalid_dates, ansi_quotes, error_for_division_by_zero, high_not_precedence, ignore_space, no_auto_create_user, no_auto_value_on_zero, no_backslash_escapes, no_dir_in_create, no_engine_substitution, no_field_options, no_key_options, no_table_options, no_unsigned_subtraction, no_zero_date, no_zero_in_date, only_full_group_by, pad_char_to_full_length, pipes_as_concat, real_as_float, strict_all_tables, strict_trans_tables)




{kind=link}
{kind=link}
{kind=link}
{kind=link}